Site Architecture & Internal Linking: How to Do it Properly
Posted: February 8th, 2019
There are many different aspects to SEO, as there are many different factors involved in a search engine’s ranking algorithm. However, site architecture and internal linking are one of the fundamentals, as this is what allows search engines to view and assess your site in the first place.
So, how does a search engine like Google view and analyse your website?
It uses something called a crawler (also known as a “spider”).
A crawler is an internet bot that reads the HTML of a site to determine its content and quality. This information is then fed into the search engine algorithm that determines where a page will rank for a specific keyword.
A crawler typically starts on the homepage of a site and then finds its way around via the internal links present on each page. An internal link is simply a link to another page on the same website.

This is why making sure that your site is properly structured and has sufficient, effective internal linking is important. It allows search engines to view and understand your site, and is a quality factor in itself, as it indicates that your site is easy to use. What’s more, it indicates the hierarchy of pages on your site, meaning that search engines are more likely to serve more important pages to search engine users.
Indicate page importance with strategic linking
Among other factors, the importance of a web page is indicated by the volume and quality of other pages linking to it. For this reason, the homepage of your website is likely to have the highest SEO value – external sites usually link to homepages.
When a page links to another page, some of its value is transferred. This means that pages with links from the homepage will have a higher value in Google’s eyes than pages further down the site structure. You need to take this into account when structuring your site and linking. A site should be structured like a pyramid, with the more important pages at the top. This sends a clear message to Google about which pages should rank.
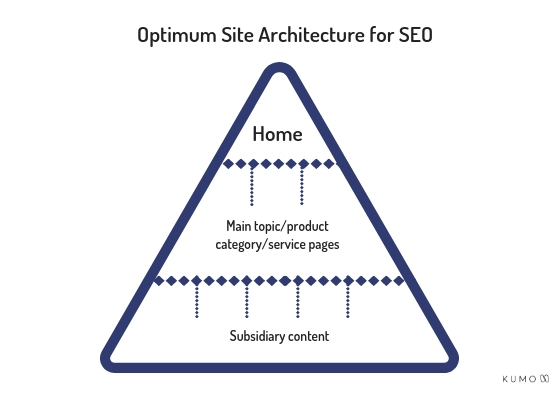
Ideally, you want your homepage to link to a limited number of main pages, so that the page value doesn’t become too diluted and the second-level pages still have high value. Less important pages (subsidiary content) can then be linked to from these second-level pages.
When devising site structure, also consider how many topics you should feature per page. Often, it is best to have one page per keyword to send a clear message to search engines. On the other hand, you don’t want to have too many top second-level pages, as they will all be of a lower value.
When adding links, think about how “deep” into the website a page is. I.e. how far down the pyramid. If you have to click through loads of other pages to get to a page, it is pretty far down the pyramid. This will make it very difficult for users to find, and will also mean it has hardly any value in the eyes of search engine crawlers and indicating a messy/complex site structure. Even if it’s a fairly unimportant page, it’s good to try and keep the structure of your site simple for crawlers and users.
Create authority on a subject by linking related content
Another way in which you can help Google to understand your site is by linking related pages to one another.
For example, part of your business might be devoted to selling teapots. You would have your main page about teapots, with a link from the home page to emphasise its importance. But you might also have blog posts about teapots: the different types, classic designs, the history of the teapot, etc.
In the blog posts, you can link back to the main teapot page to indicate to Google that it is the main teapot page. But you could also link to related blog posts to show that the pieces of content are about the same subject.
One good way to do this is to use blog categories and have the different categories show up in a sidebar on any given blog post – this is a standard feature of WordPress, for example.
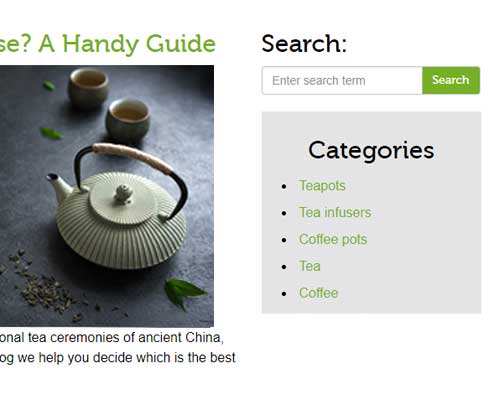
Linking in this way helps search engines to understand which content is related and helps to show the breadth of content and expertise your site has on a certain subject.
Place more important links higher up on the page
The location of links on a page also makes a difference to the value they hold. Essentially, the nearer the top a link is, the more weight it carries. For this reason, it might be a good idea to link to a main service page in the first paragraph rather than in the last, or in the footer.
Keep your URLs simple and your anchor text relevant
When you add an internal link to your site, you’re sending a search engine crawler down a little pathway to a different page. Once they’re on the page, it’ll be clear where they are, but it’s always nice to tell them where they’re going first.

The first was in which you do this is by using relevant anchor text. Anchor text is the text the user clicks on to follow a link. For search engines, this is the text that is wrapped in the <a> HTML tag. It may seem obvious, but your anchor text needs to be relevant to the page it is pointing to. Like a little signpost signalling where the link leads. However, if you have multiple links to the same place on one page, it’s best to have a few different anchor texts so it doesn’t look like you’re trying to spam search crawlers with keywords to manipulate them.
Another signpost reassuring crawlers that they’re going in the right direction is the link URL. Not only should the link URL contain an indication of what the page is about, but it should also be fairly simple and not too long. Basic rules for URLs:
- Relevant
- Short as possible (without sacrificing relevance)
- No non-ASCII characters
URLs – some good examples:
www.thehotdrinkscompany.com/teapots
www.thehotdrinkscompany.com/teapots/infuser-teapots/
www.thehotdrinkscompany.com/red-infuser-teapot-logo
URLs – some bad examples:
www.thehotdrinkscompany.com/dusiesh4h3rjhiosu/
www.the hotdrinkscompany.com/teapots/§sale/
www.thehotdrinkscompany.com/teapots/infuser-teapots/red-infuser-teapots/red-infuser-teapots-with-lids/small-red-infuser-teapot-with-logo/
You can use your intuition here – URLs that look neater and make more sense to the human eye will be more search engine friendly too!
Make sure you don’t have any orphaned pages
An orphaned web page is a page on your website that has no internal links to it and is therefore only accessible by typing the URL into the browser address bar. These pages are sad pages because usually nobody can find them, whether they’re human users or search engines.

Orphaned pages are bad for two reasons.
Firstly, users can’t find them – so what’s the point? You could have loads of great information or products on that page, but if there are no links to it then no one will ever see it.
Secondly, search engine crawlers may not be able to find or index an orphaned page. Because a crawler starts at the homepage of a site and follows the links, if a page has no links to it then the crawler won’t know it’s there. It probably won’t make it into the search engine’s index, so it won’t even show up in search results.
Don’t leave your pages out there all alone!
Make sure your internal links are accessible to search engines
There are a few things you need to watch out for when creating internal links on your website. There are certain situations in which search engine crawlers will either not be able to view or not be able to follow your links. These situations are:
1) Links embedded in JavaScript, Flash or iFrames
If your site uses any of the above, then it’s possible that some of your links aren’t accessible to crawlers. If this is the case, you might want to consider no longer using this format or placing your internal links elsewhere.
2) Links to content that’s hidden behind a form
A technique that many companies use to collect valuable contact information about potential customers is using a form where you have to enter, for example, your email address before you can access a white paper or report. From an SEO perspective, that link to the content is hidden within the coding of the form, so it can’t be accessed and indexed by search engines. That’s not necessarily a problem if it’s not a key piece of content that you want people to be able to find, but if you want it to show up in search engines, it’s worth having a rethink.
3) Links to URLs that are blocked by robots.txt or have a noindex tag
If you’ve signalled to search engines that they shouldn’t crawl and index a page, either using the robots.txt file or a noindex tag on the page, then telling them to go there by adding an internal link is confusing and/or counter-productive. If the URL you are linking to is disallowed in robots.txt, you’ve given instructions to search engine crawlers not to follow a link to that page and crawl it. You may want your users to go there, though, in which case you can link to it.
However, bear in mind that if there are multiple links to it, then search engines might deem it as a valuable page, disregard the robots.txt directive and crawl the page anyway. The same is true for pages that you have asked search engines not to index by including a “noindex” tag in the HTML – if there are lots of links to the page, it may end up getting indexed. You can learn more about robots.txt and its limitations here.
In Conclusion
So the main things to remember when setting up your site structure and adding internal links are:
- Structure your site like a pyramid
- Only add links from the homepage to a few main pages
- Link pages with related content
- Create simple URLs and relevant anchor text
- Watch out for orphaned pages
- Review JavaScript, Flash, iFrames, forms, robots.txt and noindex tags in relation to internal linking
For more SEO tips, check out the rest of our Beginner SEO series!
Author Biography
Rachel
Rachel has been working at Kumo since the start of 2018 and is a Search Engine Marketer and Head of Content. She makes sure all Kumo's clients always have fresh, engaging content that helps their websites rank and attract links.
She is also fluent in German, which comes in handy for any German websites that need content and SEO work!
Company Number: 07865143 | Company VAT: 177073296