Robots.txt – Everything You Need to Know
Posted: November 20th, 2018
In this edition of our Beginner SEO series, we discuss the Robots.txt file.
When it comes to crawling your site, the robots.txt file is one of your biggest assets. It exists primarily to inform search engine spiders and other bots which parts of your site they can and can’t access.
It’s a file that is supported, and for the most part, obeyed by all of the major search engines. That means that any rules you specify within it will be taken into account when it comes to crawling your site.
What Is a Robots.txt File? What Does It Do?
Short answer: Basically, a simple text file containing directives for bots.
A list of instructions is always a help when you’ve got a whole world wide web to check over. Search engine bots in particular love robots.txt files as they allow them to easily distinguish which pages should be available for public consumption.
Why Do I Need It?
Providing everything is set up and implemented correctly, robots.txt can be extremely handy in a number of instances.
Duplicate Content: Especially for eCommerce stores with a number of URLs using query strings. Canonical tags should be the priority, but directives in your file can help, too.
Areas Not Meant for Public Consumption: Staging and dev sites, as well as any internal documents that might be hosted on your domain, spring to mind.
Preventing Certain File Types from Being Indexed: Some people don’t like things like PDFs and images being indexed.
If you don’t want to hide anything from search results, you don’t need one. You could have one that simply lets every crawler find everything if you like.
It’s worth noting that URLs excluded from indexing in robots.txt may still end up being indexed if search engines deem them valuable.
Links pointing, both internal and external, to a page are the biggest reason this might happen.
How to Check for One
Before a bot crawls your site, it checks to see if you’ve left it any instructions. They do so by looking for your file on the root of your domain.
Every site follows the same practice, like so:
https://www.kumodigital.co.uk/robots.txt
https://www.youtube.com/robots.txt
https://www.bbc.co.uk/robots.txtThe basic premise remains the same with each site –
domain.tld/robots.txtThat means it is pretty easy to check out your own – just append /robots.txt to the end of your domain and see what happens.
You’ll find one of four scenarios occurs:
- A file detailing which parts of your site spiders shouldn’t crawl
- A default file automatically generated by your content management system or uploaded by your site developer
- You’ll see an empty document signified by a blank page
- You’ll be served with a 404 page, signifying your site doesn’t have a file uploaded, full stop
If it’s any of the latter three, you might be considering changes. If you’ve got parts of your site you don’t want indexing, your robots.txt file is the place to say so.
You can also see your robots.txt file using Google Search Console under Crawl -> robots.txt Tester.
Locating the File
It’s one thing looking at your robots.txt file – finding and editing it is another. There are several places where you may find it waiting to be edited.
FTP
This is a sensitive area to be poking around in. If you find yourself here, don’t touch anything you’re unfamiliar with. You could break the entire site.
If you have FTP access to your site, it’s pretty easy to find the robots.txt file. It lives on the root, so it shouldn’t take more than one or two clicks.
Here’s an example of the file being available without having to click anything else:
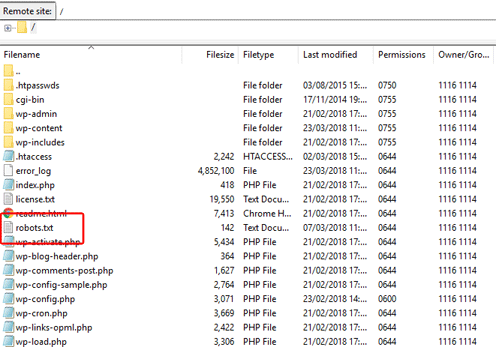
If it isn’t immediately available, it’s usually in a ‘public’ folder, like this example:
Hosting Account
Alternatively, head over to your hosting account. You should see something similar to this:
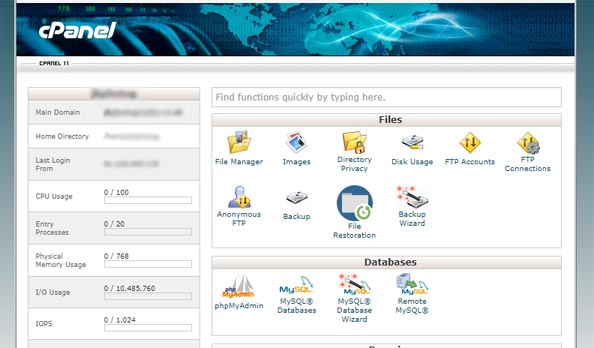
Select File Manager and locate the robots.txt file. Make sure you don’t delete it.
You can delete everything in there and replace or just add to what’s already in place.
WordPress Virtual File
If your site is on WordPress, you may have found a robots.txt file that looks something like this:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpIf you can’t find where it is in your files, no need to panic. WordPress automatically creates a virtual robots.txt if one isn’t detected.
This essentially means you don’t have one, so WordPress provided something in place.
How to Write
Crafting a robots.txt file is easy in explanation, but can be a bit tricky if you aren’t entirely sure what you are doing.
Use a text editor – Notepad will do the job just fine. You can also use online editors, such as editpad.org. Programs like Word tend to save documents in proprietary formats, such as .doc or .docx, which often don’t conform to character rules that crawlers understand.
The primary example is quote marks. There’s a big difference between “ and “ for spiders.
Note that everything is case-sensitive, including the name of the file. Don’t use any capitals when you’re saving it.
The robots.txt file is cached. It’s usually updated every day, but you can resubmit in Search Console to make sure your new version is refreshed straight away.
Understanding Syntax
First and foremost, you’ll have to know how to dictate which parts of your site should and shouldn’t be crawled.
You’ll need the following syntax:
User-agent: [This is the name of the robot you’re trying to communicate with]
Disallow: [A URL path that you don’t want crawling]
Allow: [A certain path of a blocked folder or directory that should be crawled]As an example, if we want to block Googlebot from a blog category directory, apart from the SEO section, our robots.txt file might look something like this:
User-agent: Googlebot
Disallow: /blog/category
Allow: /blog/category/seoThe robots.txt Tester in Search Console can be used to test our rules. Let’s check this one.
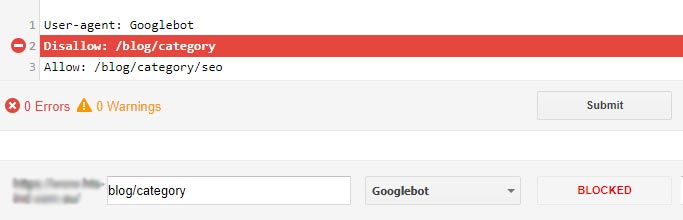
As desired, Google is confirming that the /blog/category/ category folder of our site is blocked…
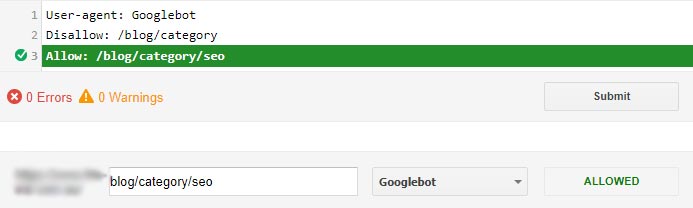
… but the SEO category is good to go. Exactly as we wanted – it works.
To be safe, we should probably check that other categories aren’t allowed.
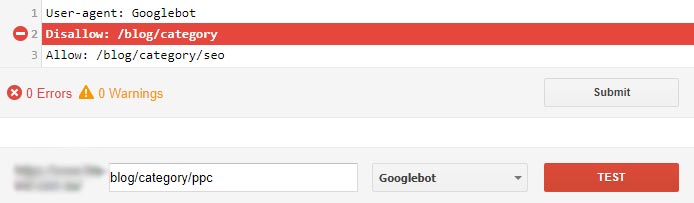
There you have it. We’ve successfully disallowed a directory with the exception of an SEO blog category.
Some search engines take note of additional directives, such as “crawl-delay”. This increases the time between crawling and is less heavy on your server.
Google actually ignores it. With that in mind, a lot of site owners ignore it, too. Bing et al pay attention, but it’s not really an issue unless your site is taking a hammering.
It’s also worth noting that if you use directives for specific crawlers, you’ll need an empty line between each, like so:
User-agent: Googlebot
Disallow: /blog/category
Allow: /blog/category/seo
User-agent: Bingbot
Disallow: /blog/category
Disallow: /blog/category/seoWhere to Put It
The robots.txt file goes in the root of your domain. Of course, if you’ve already found yours, you can simply replace the content in it with your new rules.
If you didn’t find one, it can be uploaded using a few methods.
FTP
Once you’ve written your file, you can simply drag it into your FTP client window.
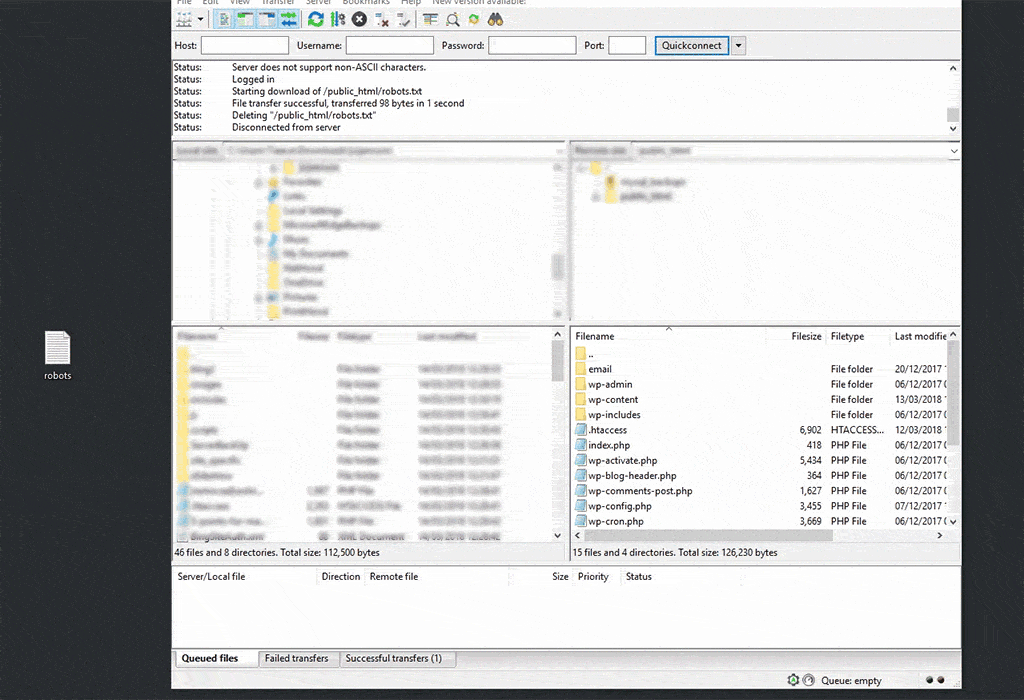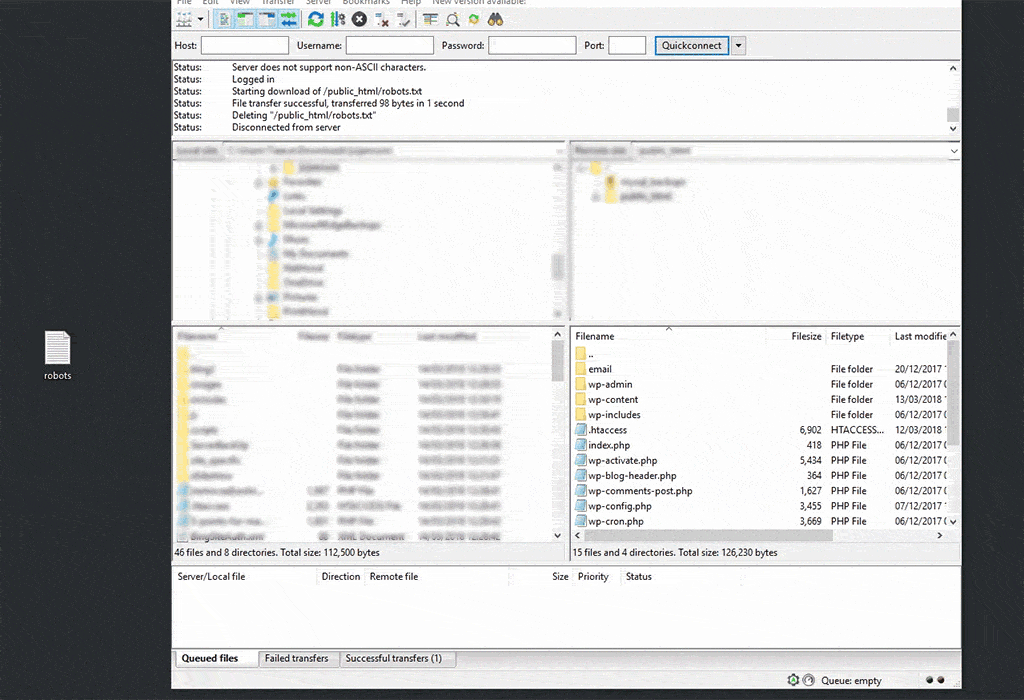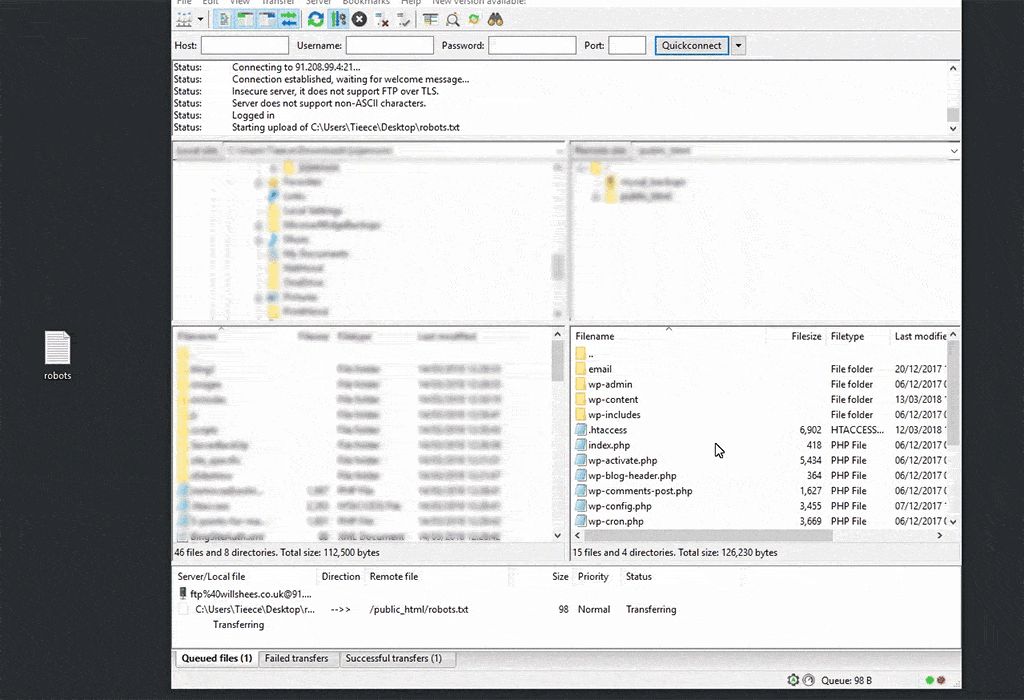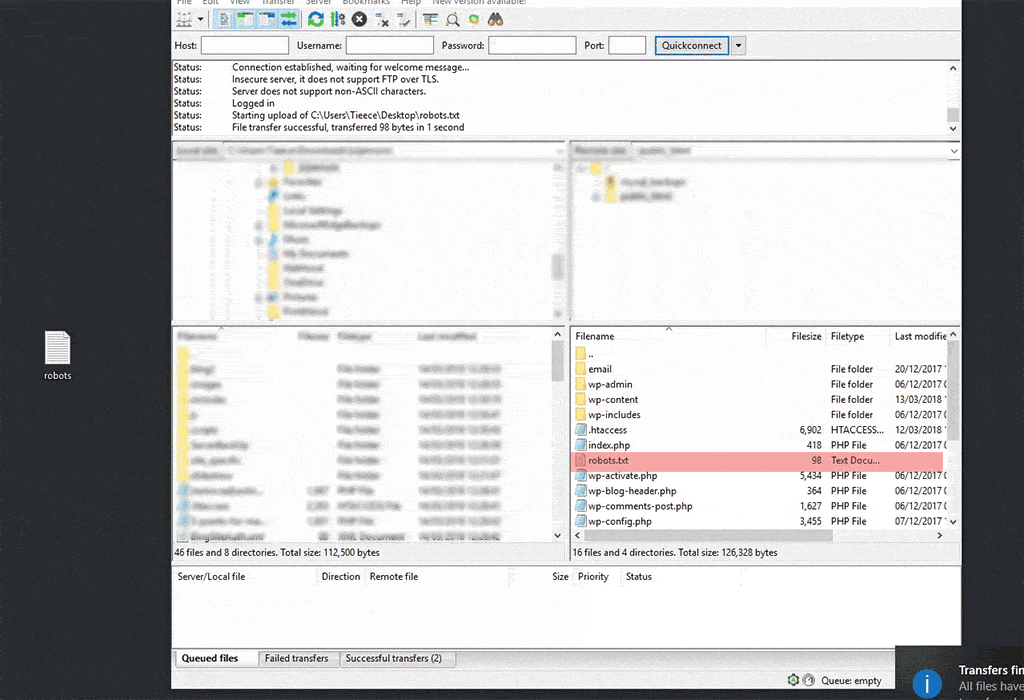
Remember that if it isn’t on the root, it isn’t going to work.
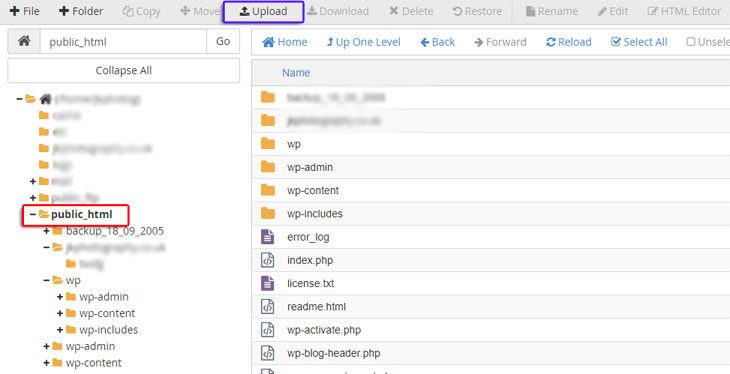
Hosting Account
Locate the public HTML folder of your site, as shown by the red box. Select this directory and click the upload button to begin implementing your file.
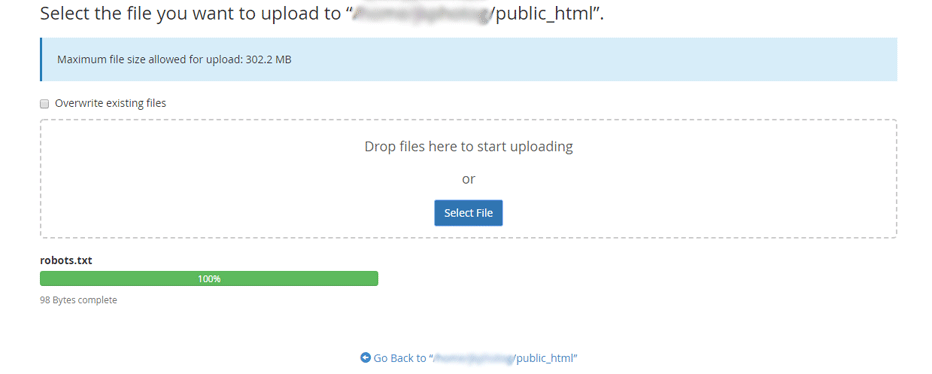
In cPanel, you’ll be presented with an option to drag or select a file. Take your pick, and your file will be uploaded.
Yoast
If your site is on WordPress and you have the Yoast SEO plugin installed, you might be able to upload a robots document without having to poke around in source code and server files.
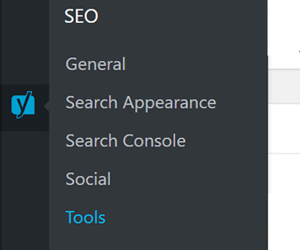
Assuming both your admin account and the Yoast plugin have permission to edit server files, select Tools from the Yoast menu.
You should see a list of options, including File Editor.
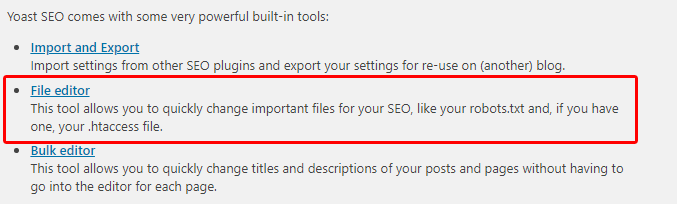
Find the section labelled “robots.txt” and paste in your rules.
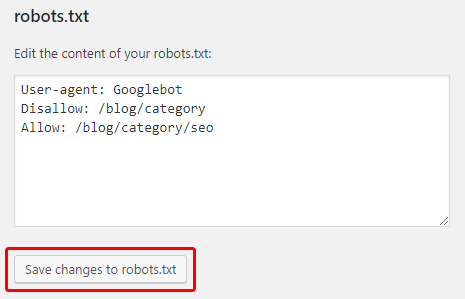
Click the Save Changes to robots.txt button
Validation
As we mentioned earlier, you can validate your uploaded robots.txt file using Search Console.
If you’ve done everything right, including making sure you placed it in the right directory, you can go ahead and insert your blocked path.
Click the TEST button, and it should return the bright red bar highlighting which rule is preventing the URL or folder from being crawled.
Potential Pitfalls
Up to this point, we haven’t really been met with any challenges. We’ve had a few things to look out for, but generally not too much to make us scream.
A simple slash may seem like a small detail, but it can end up being far from that.
Being as strange as I am, I’ve decided to start a travel business that only goes to places called Nottingham. I originally started out with just two destinations – Nottingham, UK and Nottingham, Maryland, USA.
Each has a landing page:
https://www.nottingham-travel.co.uk/nottingham/
https://www.nottingham-travel.co.uk/nottingham-md/I slowly began to offer more destinations, all called Nottingham, of course, and had a respectable six destinations. As well as my original two, new locations in Indiana, New Hampshire, New Jersey and West Virginia became available.
Again, they had their own landing pages:
https://www.nottingham-travel.co.uk/nottingham-in/
https://www.nottingham-travel.co.uk/nottingham-nh/
https://www.nottingham-travel.co.uk/nottingham-nj/
https://www.nottingham-travel.co.uk/nottingham-wv/Unfortunately, a couple that refused to pay after ordering room service got me banned from using the hotel I provided with my Nottingham, UK packages.
With that in mind, I decided to hide the landing page from crawlers for a while. I wanted to keep it live to drive enquiries for when we were back up and running.
A host of images and subpages lived in the same directory, so I simply amended the robots.txt file to read:
User-agent: *
Disallow: /nottinghamJob done. Until I noticed that traffic suddenly stopped and no leads were coming in. There must have been a problem.
Check this out:
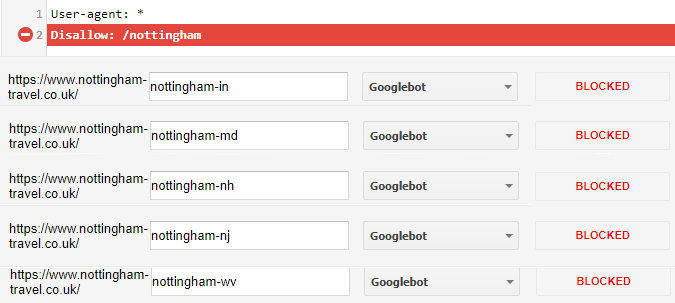
I’d managed to stop every destination page from being crawled!
Special Characters
There are four main characters that help Googlebot understand your robots.txt file a little better.
| Name | User Agent | Fucntion | Helps To | Example |
|---|---|---|---|---|
| Trailing Slash | / | Indicates the end of a directory | Allow URLs and directories partially beginning with a blocked resource to be crawled | Disallow: /directory/ |
| Dollar Sign | $ | End of string – excludes only URLs up to the specified location | Allow URLs and directories associated with disallowed resources to still be crawled | Disallow: /all-shoes$ |
| Asterisk | * | Wildcard – replacement for anything | Indicates that any URL or folder that can be found by replacing the asterisk with a specific location | Disallow: /*.pdf |
| Ampersand | & | Blocks specific, non-consecutive, query parameters | Ensure non-indexation of query strings | Disallow: /*?&id |
Our Nottingham Travel robots.txt file should have used these rules to ensure the crawling of our US-based locations continued:
User-agent: *
Disallow: /nottingham/or
User-agent: *
Disallow: /nottingham$The second rule, however, wouldn’t have stopped our UK subpages from being crawled.
Beware of Previously Indexed Content
If you have an indexed directory that you want gone from the SERPs, robots.txt inclusions alone don’t guarantee that.
In fact, in most cases, your pages will still be around when people search.
It’s an assumption that a fair few have been guilty of down the years, and it’s the same with noindex tags, too.
It’s best practice to request the removal of URLs or directories if they’ve already been crawled prior to your file revision.
Head over to Search Console and choose Remove URLs from the Google Index menu.
Click the Temporarily hide button and enter your URL or directory. You can change the request type with the dropdown menu.
Can I Exclude a Specific Page in Robots.txt?
You could, but it’s generally not a great idea.
Imagine how long some of the robots.txt files out there would be if every site did this.
As a rule of thumb, try to keep your robots file at the directory level. Stick with the trusted noindex tag for specific URLs.
Some people have been known to use a noindex directive, to some success, in a robots.txt file. Google’s John Mueller weighed in on the debate back in 2015 on social media.
TESTED: no need for disallow if using noindex in robots.txt. As long as @google supports it… @deepcrawl @JohnMu https://t.co/CtALatZhhB
— Max Prin (@maxxeight) 1 September 2015
The response was pretty concise.
@maxxeight @google @DeepCrawl I’d really avoid using the noindex there.
— John ☆.o(≧▽≦)o.☆ (@JohnMu) 1 September 2015
It’s not a statement saying that it isn’t supported by Google. More a word of advice from somebody well in the know.
There are two main points to remember:
- Disallow and noindex can mess with each other – if a page is blocked by robots.txt, the meta robots tag won’t even be seen
- Other search engines, Bing in particular, don’t support the noindex directive in a robots file, so pages would still be indexed elsewhere
And Done
In 99% of cases, you’re going to need a robots.txt file. It can be daunting to begin with, especially if you manage to block your entire site or important pages.
Get it right and you can reap the benefits of improved crawl rate optimisation and stop a host of issues, including duplicate content and indexed junk.
Author Biography
Tieece
As an SEO Executive at Kumo since 2015, Tieece oversees the planning and implementation of digital marketing campaigns for a number of clients in varying industries.
When he's not crawling sites or checking Analytics data, you'll often find him (badly) singing along to music that nobody else in the office is in to.
Tieece holds a number of digital marketing accreditations including Google Partners qualifications.
Company Number: 07865143 | Company VAT: 177073296