A Complete Guide to Crawl Rate Optimisation: What Is It & Does It Matter?
Posted: March 21st, 2018
Crawl rate optimisation is the concept of ensuring that search engines efficiently crawl and index pages, particularly ones that are important to your website.
Whether your site is a 10-page blog, an informational portal, a national e-commerce store, or anything else, optimising for spiders and bots can effectively point them to your most valuable pages.
There are tons of crawlers out there. For the purpose of this post, I’m going to concentrate on Googlebot, considering it’s the biggest and baddest.
Assessing URLs before It Begins
Even for the seemingly infinite reach of Googlebot, the web is far too big to go out and crawl and index in its entirety. The fact is, when bots hit a site, they have limited resources. Sounds odd considering Google reported having 130 trillion indexed documents in November 2016, but key decisions have to be made, including:
- Which pages and/or documents should be given priority for crawling
- Which pages and/or documents should be ignored completely
- Should a recently crawled document be crawled again soon
These are questions posed to every crawlable site, page and resource on the web. Smaller sites may be ok, provided there is enough crawl budget to cover every document. Google’s Webmasters Blog explains that:
“…if a site has fewer than a few thousand URLs, most of the time it will be crawled efficiently.”
Larger sites, though, have some serious thinking to do. It’s also best practice for sites falling under “a few thousand URLs” to optimise effectively.
What Is Crawl Budget?
Crawl budget is essentially the number of times a search engine will attempt to crawl a site in a given timeframe. It is determined by taking into account factors impacting crawl rate and crawl demand.
Crawl Rate Limit
Googlebot’s number one job is to collate pages on the internet to use within SERPs. It has to do this without damaging user experience, too. With that in mind, crawl rate limits dictate the number of connections used to crawl a site, as well as the time period between fetches.
All URLs will cost crawl budget, including CCS, JavaScript, AMP and hreflang tags.
There are two main components, as explained by Google’s aforementioned blog post.

It’s pretty straightforward and makes perfect sense, really. In most cases, it’s not really advisable to limit Google’s crawl rate. After all, why would you not want your pages crawling and indexing?
Perhaps one of the only exceptions is if Googlebot is hampering user experience by slowing down your server. To limit crawling, go to Search Console, click the settings cog button in the top right corner and choose Site Settings.
Next, use the slider to limit crawl requests per second and time between requests.
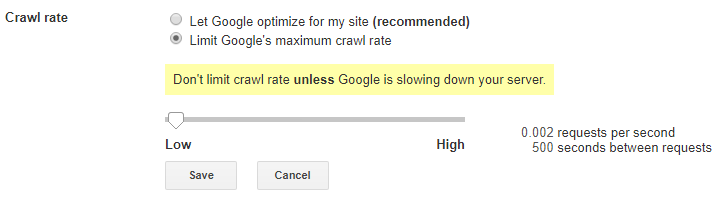
Then Save. Googlebot tends to be smart enough to be able to decipher any impact on UX, so it’s likely you’ll rarely, if ever, need to limit crawl rate.
Crawl Demand
Crawl rate limit isn’t always met, especially for smaller sites. This doesn’t necessarily mean that Googlebot will come in leisurely picking up and indexing every page and resource on your site. Don’t forget, there’s a whole World Wide Web out there that needs crawling.
Crawl demand is made up of two primary factors: popularity and staleness.

There is an additional point when it comes to demand. Moving a site, changing URLs, and other site-wide events mean that pages have to be reindexed. This usually leads to an upturn in crawl demand in order to accommodate.
A combination of limit and demand allows Google to define the crawl budget. Its official take is
“we define crawl budget as the number of URLs Googlebot can and wants to crawl.”
Crawl Stats in Google Search Console
Google Search Console offers some insights into your site’s crawl budget.
Log in to Search Console and choose Crawl Stats from the Crawl Menu.
From there, you’ll be able to see Googlebot activity from the last 90 days.
Pages Crawled Per Day
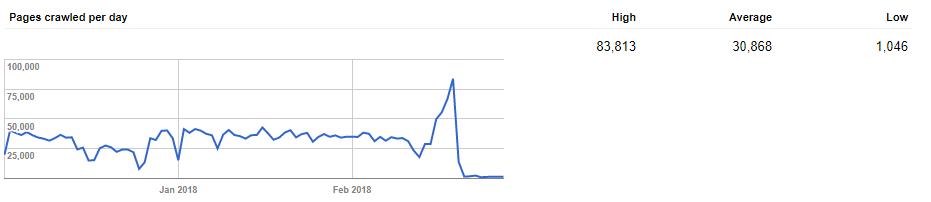
The actual number of pages crawled by Googlebot each day. This is the clearest indication of your site’s crawl budget, especially if you have more pages than are actually being looked at.
You can see the highest number of pages crawled for one day, the lowest and an overall average.
Strictly speaking, you can’t change how often Google crawls your site. That doesn’t make this graph useless, though. In fact, there could be vital information within it, particularly massive fluctuations.
Granted, ups and downs are normal. It’s not even of too great a concern to see moderate differences between days, as long as roughly the same number of pages are being reported as crawled each day.
Sudden changes, spikes or drops could be indicative of crawlability issues. But why?
Drops
Sudden drops in the graph could be down to a number of things. If you see a sudden big drop, check for the following.
Broken/Unsupported Code or Content – Only a possible issue if you’ve recently implemented new code (could be HTML, CSS, XML, etc) that is incorrectly written. You can use W3’s validators to check whether your code is working as it should

It’s worth noting that not every error thrown up here will have a negative impact on crawling.
Blocked by Robots.txt File – Your Robots.txt file is a document that outlines any crawling restrictions to bots and spiders. It can be a best friend for crawling, but it can also be an enemy
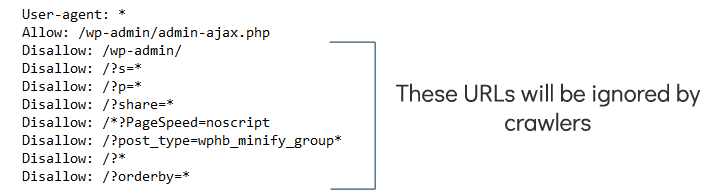
If bots are blocked from certain pages, they won’t be crawling them. If you’ve blocked resources that Googlebot relies on, or URLs that you want indexing, take them out of the robots.txt file immediately.
Spikes
New Code or Content – That recently implemented code we spoke about for contributing to drops can also result in more pages being indexed. This is usually most notable after a site upgrade that brings code improvements
Remember that Google is openly a big fan of fresh content. Every time your site is updated, Googlebot is alerted. So, theoretically speaking, more fresh content equals more crawling.
Crawling Allowed by Robots.txt File – Most content management systems will create a default robots.txt if one isn’t implemented. WordPress, for example, includes this for sites without one:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Blocking admin areas is, of course, desirable, but what about pages that you don’t want indexing? You’ll have to actively state this. We’ll cover the robots.txt file in more detail later on.
Ultimately, don’t panic unless ups and downs are sustained. One big drop or spike isn’t necessarily a problem.
Kilobytes Downloaded Per Day
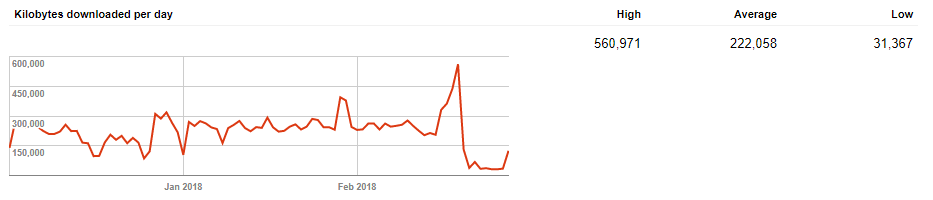
Your pages are downloaded each time they are crawled. This graph represents the total number of kilobytes Googlebot has processed.
Again, high, low and average stats can be seen. You should generally find that downloaded kilobytes match up to pages crawled on a corresponding day.
In all honesty, there isn’t a whole lot to take away from this by itself. The total number depends entirely on your site and page size. A low number isn’t an automatic tell that Googlebot isn’t crawling your site.
In fact, it could be a good sign. If your pages are smaller in size, you’ll probably get more indexed quicker.
On the other hand, high values could illustrate that Google is fetching more pages. It could also be that pages have more weight than desirable.
Time Spent Downloading a Page (In Milliseconds)
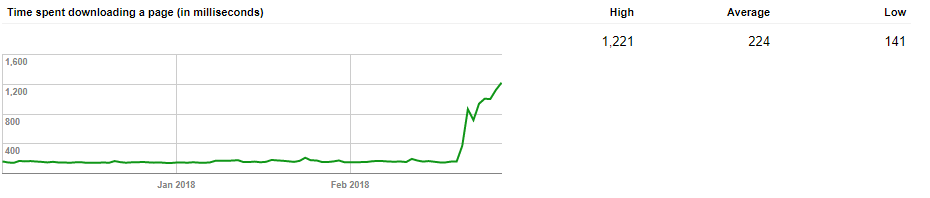
Before anything else, we’ll clear up that this graph is entirely unrelated to site speed. Back in 2015, John Mueller confirmed that it was “nothing related to rendering the page itself” and instead “just time to complete an HTTP request”.
Lower values might suggest that Googlebot is getting through your pages pretty quickly. Good news for indexing and getting your pages in the SERPs. For the record, a millisecond is a thousandth of a second; so there are a thousand milliseconds in a second.
Unfortunately, it’s a metric that you can’t do much to change, but you can use it to your advantage, especially when used in conjunction with the Kilobytes downloaded per day graph.
If both graphs are showing large values, Googlebot is spending time hanging around your site for a long time. This is a drain on crawl budget, especially for larger sites.
You’ll want to reduce the amount of time bots are on your site. That brings us back to the robots.txt file and blocking unnecessary pages. Irrelevant pieces of code and content can also get the chop.
Don’t be rash, though. Some of this may be a big player for your SEO game. Make sure you’re not getting rid of something giving you an edge over a competitor or vital for Googlebot to actually crawl a URL.
Optimising for Googlebot
Crawl rate isn’t a direct ranking factor. Sites that have more pages indexed or are visited by crawlers more often aren’t favoured in the SERPs.
Having your pages indexed and offering more options for search engines to display, however, gives your site a better chance of appearing for given search terms. Here are some tips for encouraging Googlebot to check out more pages more often.
Ensure That Pages Are Actually Crawlable
Makes sense, doesn’t it? In extremely simple terms, if pages aren’t crawlable, they’re not going to be crawled.
Certain web development techniques and media, such as AJAX and Flash, can sometimes get in the way of crawling. It’s usually a good idea to avoid them in navigation elements, as crawlers can have a tough time following them. If a crawler gets stuck, it might not be able to find another way into your site.
JavaScript can cause similar problems. It’s a vital component for many sites, which isn’t a problem. However, links should be HTML-based to aid Googlebot. Again, try to avoid using it within the site’s nav.
Reduce Crawlable URLs
Without directives, Googlebot will attempt to follow every link it can find and index each URL it comes across. There are a number of reasons you may not want every single page to be indexed. Pages could be:
- Customer account pages or an eCommerce basket
- Duplicate URLs with query strings and parameters
- Internal and password-protected documents
- Pagination
- Valueless content
There are two tags you can use to stop these budget-wasting pages. The noindex meta tag and X-Robots-Tag tell Googlebot that these pages shouldn’t be crawled and indexed.
The noindex tag can be placed in the <head> section of the page and is written:
<meta name="robots" content="noindex">
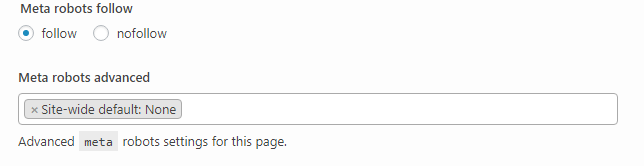
Of course, other directives, such as nofollow may be contained in the same robots tag. Some CMs platforms and plugins allow easy configuration. Yoast for WordPress being the prime example.
You can do it from the exact page by scrolling to the Yoast section and clicking the advanced section cog icon.
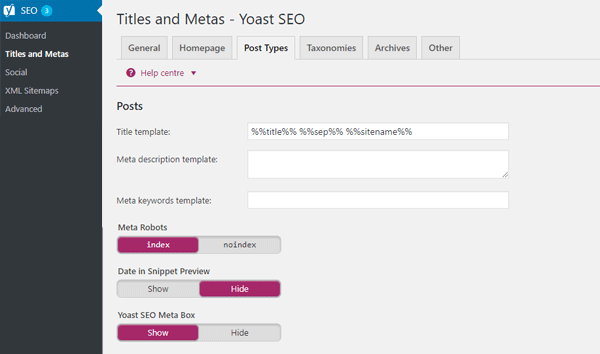
You can also set by post types and taxonomies from the Title and Metas section.
The X-Robots-Tag is slightly different as it is placed in the HTTP header response, like so:
X-Robots-Tag: noindex
If you do use the X-Robots-Tag, don’t include impacted in your robots.txt file. Googlebot won’t get far along the road enough it actually see it if you do.
Upload a Robots.txt File
We briefly touched on the robots.txt file earlier. There are several ways in which it can help with your site being crawled. In fact, it’s one of the most useful documents bots find.
Disallow rules can be configured within the robots.txt file that inform crawlers which documents you don’t want being accessed. Rules can be set up by a specific user agent or for everyone.
There are a fair few bots and crawlers out there, but arguably the most popular ones are:
| Indexer | User Agent |
|---|---|
| Googlebot | |
| Bing | Bingbot |
| DuckDuckGo | DuckDuckBot |
| Baidu | Baiduspider |
| Yandex | YandexBot |
| Ahrefs | AhrefsBot |
| Majestic | MJ12Bot |
| Screaming Frog | Screaming Frog SEO Spider |
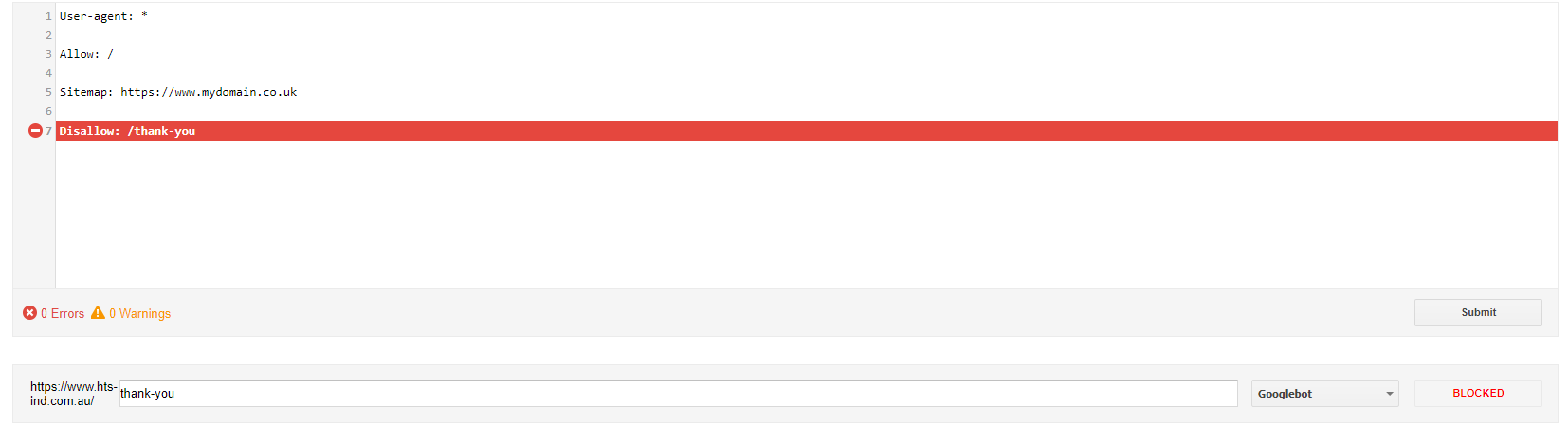
To stop one from accessing your site, include a disallow rule in your robots.txt file. For example, to deter Googlebot from a contact form contact page, you might write something like this, depending on the URL:
User-agent: Googlebot
Disallow: /thank-youTo deny access to multiple bots, use more user agent directives, like so:
User-agent: Googlebot
User-agent: Bingbot
User-agent: DuckDuckBot
Disallow: /thank-youOr to simply deny access to all bots, use an asterisk:
User-agent: *
Disallow: /thank-youFile types, directories and paths can also be blocked. It’s important to note that any directory rules should include a trailing slash to highlight that it is a directory rather than a page.
It is best practice to include a reference to your XML sitemap as it enables crawlers to pick up a full list of URLs you do want indexing.
Your robots.txt file lives on the root of your domain. It’s public, too, so don’t try to hide things in there. People will be able to see it if they really want to.
You can use the robots.txt tester in Search Console to check whether URLs are allowed or disallowed for Googlebot.
A “crawl-delay” directive in your robots.txt file is useless. Googlebot doesn’t process it.
Ensure Healthy URL Structure and Makeup
Googlebot loves straightforward, easy-to-read URLs. Not only that, they help to keep your indexed pages clean and easy to follow.
Any URL strings that contain non-ASCII characters, underscores, capital letters and parameters can get confusing for some crawlers.
Non-ASCII characters can be invalid characters, underscores aren’t always identified as separators, and parameters are usually an indication of duplicate, expanded or narrowed content, such as product query strings and identifiers. Think of the classic question marks (?), equals signs (=) and ampersands (&).
If these issues simply can’t be avoided, such as cases of eCommerce filters, make sure your pages are canonicalised, disallowed in robots.txt or set to NoIndex appropriately. This way, bots won’t waste their time going through unnecessary URLs.
Avoid Redirects
Redirects, and in particular redirect chains, are a sure-fire way to make sure your crawl budget gets wasted. Remember, every time Googlebot follows a link, a percentage of your crawl limit goes with it.
In fact, if there are multiple 301 and 302 redirects in a chain, crawlers can drop off and essentially never even reach to final destination, no matter how great the page or content might be.
Redirects are best avoided, but if they have to present, try to keep them well below two in a chain.
My favourite tool for identifying redirects is Screaming Frog. Enter your site, head to the Redirection tab and select Redirection (3xxx) from the dropdown menu.
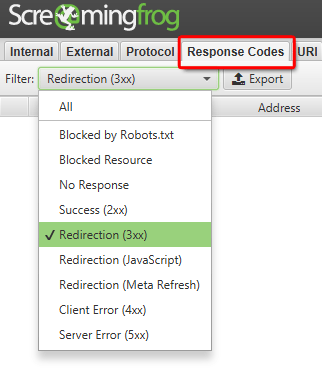
For longer chains, you can actually download a spreadsheet from within Screaming Frog. Just click Reports and Redirect Chains to download a CSV.
Fixing any issues highlighted helps to preserve crawl budget and can improve the load times of the final destination dramatically.
Check Your Site Content
Google has revealed that duplicate, low-quality and spam content can have an adverse effect on crawling. There’s also the fact that Google’s Panda algorithm isn’t a fan either.
Every single page on your site should provide unique, valuable content. If a page doesn’t, there aren’t many occasions that there’s any point in it even existing.
The more low-quality pages Googlebot encounters, the quicker it’s going to decide it’s time to pack up and move on – nothing to see here.

Source: http://www.cc.com/
Get Your XML Sitemaps in Shape
XML sitemaps are designed to tell crawlers where your pages are and how to find them. Their job is literally to get you indexed. That’s why you need to make sure that yours is:
- Always up to date
- Submitted to Google Search Console
The easiest way to make this happen is to have sitemaps automatically generated. A lot of CMS platforms include this functionality as standard, or have plugins that will do it for you. Alternatively, you can use an XML Sitemap Generator tool.
Take a look at the end result to ensure that the pages you want to be in are actually in and there are none in there that you don’t want.
You can add and test your sitemap in Search Console. Select Sitemaps from the Crawl menu. You’ll also be able to see how many of your submitted webpages have been indexed.
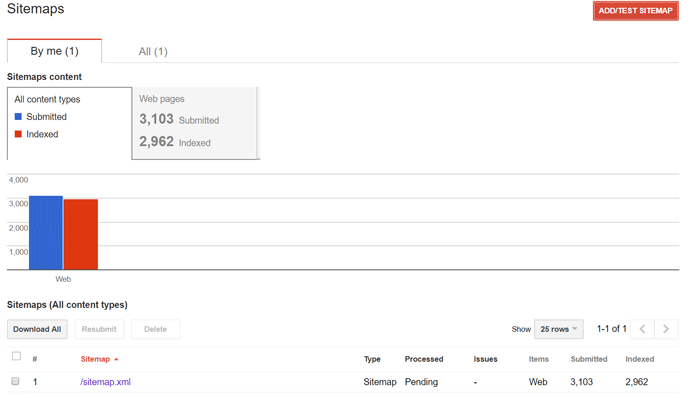
Search Console now informs of sitemap errors via email. In instances of URLs marked with a noindex or a canonical tag, you’ll get this data reported back to you. This allows you to remove unnecessary URLs and reduce Googlebot’s workload.
Keep an Eye on Parameters and Faceted Navigation
Search parameters are essential, and sometimes unavoidable, for filtering, narrowing, specifying and sorting pages. However, faceted navigation is listed by Google as the number one cause of low-quality and duplicate content across the web.
Let’s take an imaginary product that comes in three colours. We’re selling it and want users to be able to find red, blue and yellow from within our site’s navigation. Our main product page is at:
https://www.myumbrellastore.co.uk/umbrellaGiven the nature of our eCommerce store, though, we’ve got some filters set up to help visitors find their perfect item.
https://www.myumbrellastore.co.uk/umbrella?colour=red
https://www.myumbrellastore.co.uk/umbrella?colour=blue
https://www.myumbrellastore.co.uk/umbrella?colour=yellowOn top of this, our umbrellas can be filtered even further, this time by size. We’re a family company and we’ve got small, medium and large ready to buy.
https://www.myumbrellastore.co.uk/umbrella?colour=red&size=large
https://www.myumbrellastore.co.uk/umbrella?colour=red&size=medium
https://www.myumbrellastore.co.uk/umbrella?colour=red&size=small
https://www.myumbrellastore.co.uk/umbrella?colour=blue&size=large
https://www.myumbrellastore.co.uk/umbrella?colour=blue&size=medium
https://www.myumbrellastore.co.uk/umbrella?colour=blue&size=small
https://www.myumbrellastore.co.uk/umbrella?colour=yellow&size=large
https://www.myumbrellastore.co.uk/umbrella?colour=yellow&size=medium
https://www.myumbrellastore.co.uk/umbrella?colour=yellow&size=smallOh, did I mention that users who display more than one colour or size, too?
As you can imagine, the number of URLs can get colossal, especially for websites with a whole load of products. What’s more, the content on each of these pages is duplicated. This can devalue the rest of a site’s content, at the same time as eating into crawl budget.
Parameters and faceted navigation elements can be set up with canonical tags and disallow rules in your robots.txt file. There’s a section of Search Console dedicated to them, too.
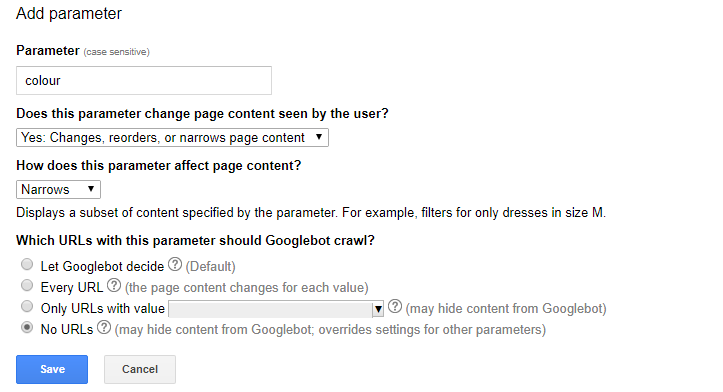
To find it, go to the Crawl section and select URL Parameters. This should be exercised with caution, though, as you could potentially hide pages from Google completely.
Build Quality Links from External Sources
Googlebot’s main mode of transport is links. When it sees a link, it follows it, finding out where it points, and in some cases, why it points there.
Building links from authoritative sources can help your crawl rate. Authoritative sites are more likely to be crawled more often. Links nudge bots to your site, which is beneficial for picking up your content.
It is widely accepted in the SEO world that the total number of inbound links is directly correlated to crawl budget.
Don’t focus on building any old link, though. Links from poor sites won’t help. They might even get you penalised thanks to Google’s Penguin algorithm.
Utilise Internal Linking Strategies
Again, Googlebot follows links. That means that good site architecture has a role to play in crawl rate optimisation. Menus, subfolders and directories are the main players but linking to one page from another page also encourages crawling.
On the other side of the coin, Google doesn’t want to follow links marked with the NoFollow attribute.
Take a look at this snippet taken from the Google Webmasters Blog.

Proof that links pointing to non-indexed pages should always be set to NoFollow. Even if you’ve got NoIndex or canonical tags in place, make sure internal links are set to NoFollow.
As far as external links go, you shouldn’t be link-building pages you don’t want indexing. If natural links are gained, outreach to the source and ask them to change it. They clearly like your site, so there shouldn’t be a reason why they’d refuse.
Keep Bringing That Fresh Content
We mentioned earlier that fresh content is great. After all, why would anybody be interested in outdated information, especially in industries that are always changing? At least that’s what we’re led to believe in theory.
Page changes alert Google, and Googlebot comes to check out your changes. A page is recrawled (or crawled for the first time), something that happens far less for sites with stale content.
So, theoretically at least, the more you pump out high-quality pages, the more often your site will be crawled.
Of course, there’s also the point that you’ll have an updated chest of rich information and valuable treasure for users, which is the whole point of keeping your site updated.
Make Sure Your Server Is Helping
Again, taken from Google’s Webmaster blog, server response time is a factor for crawl rate optimisation. It can work for or against you:
- Server responds quickly, allowing more connections to be made during crawling and, in turn, increasing the crawl rate
or
- Server responds slowly, or not at all, and Googlebot simply can’t process as many URLs, resulting in a drop in a site’s crawl rate
Whilst server speed isn’t the defining influence, good times are indicative of healthy servers, allowing for more content to be passed through the same number of connections.
For a lot of people, a quicker server is a case of paying a bit more money to their hosting provider, which isn’t ideal. There are a few tips to use to minimise the demand on the server if you don’t want to fork out additional fees:
- Use a content delivery network (CDN) to improve load speeds for traffic significant distances from your server location
- Combine external CSS and JavaScript files to reduce external roundtrips
- Lazy load or defer JavaScript, CSS and images so the real page content is loaded before anything else
- Enable Keep Alive to allow multiple files to be grabbed from the server at a time, instead of repeated requests
Quick warning – these fixes require a certain level of knowledge and know-how, and for the most part shouldn’t be attempted if you don’t know what you’re doing. There’s potential here to destroy server-side files, so it’s definitely best left to an expert.
Fix Those Broken Links
Let’s say it again – Googlebot likes to follow links. Sometimes, it can reach a dead end.

Source: http://www.simpsonsworld.com/
In this specific case, I’m referring to broken links and 404 pages. They’re also dead ends for your users, so it’s in your best interest to get them gone. You can find your site’s 404 page in Screaming Frog.
Go to the ‘Response’ tab and select ‘Client Error (4xx)’ from the dropdown menu.
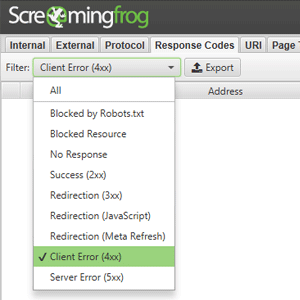
Select the ‘Inlinks’ tab at the bottom to see pages linking to dead pages and remove or replace your broken links.
Remember to make sure these broken links aren’t in your XML sitemap, too.
Keep an eye on the Crawl Errors report in Search Console for URLs that Googlebot is failing to crawl.
Optimise Images As Well
Search engines consume the web in a different way than humans. One of the primary features we have that Googlebot doesn’t is eyes.
Crawlers simply can’t read images; not to a substantial level for the time being, at least. The same principles apply to video, too.
Flash is a particular bane for Googlebot as it can’t index it, no matter what you may try.
Alt text is a key ingredient in your image crawling recipe. This HTML tag allows a brief description to be inserted and helps with indexing appropriately. Simply include a descriptive summary of your image within an alt tag in the image tag:
<img src="/image-URL/" alt="Alt text here" />
Ping Your Changes
Pinging services tell crawlers of your new pages and changes on your behalf. First introduced by Dave Winer of Weblogs.com, they’ve been widely accepted as being able to get pages crawled and indexed in the past, and many still believe they play a crucial role in quick indexing.
Unfortunately, some people out there have abused the system, with some even creating scripts invented for the sole purpose of manipulating crawlers to pay regular visits.
That’s not to say that pinging has absolutely no place today. In fact, some blogging platforms send automatic pings any time a post is edited or tweaked.
There are also a huge number of plugins available if you’re an automation advocate.
Think of it in a similar way to the “Fetch as Google” option under the Crawl section in Search Console

Almost the same functions exist. Enter details and request crawlers to come and check out your new content.
If You Haven’t Yet Done It, Get Rid of Black Hat Techniques
Search engines have evolved over time. They’ve got smarter and can now pick up on way more black hat tactics than before.
Some of these techniques may have worked wonders in the past. Some sites might not have even faced any penalty yet. The fact remains, though, that they won’t likely be of any use whatsoever in due course. That is, unless you want your site to spiral out of the SERPs.
Avoid black hat tactics such as:
- Keyword stuffing
- Hidden links
- Spun content
- Cloaking
- Link exchanges
- Low-quality links
- Private blog networks (PBNs)
There aren’t many quicker ways to put crawlers off than techniques that have been expressly recommended against. Even if you get away with it for a bit, chances are Google will catch up with you and issue you a penalty of some sort.
Making the Improvements
Crawl rate optimisation isn’t the be-all and end-all of SEO. There are hundreds of ranking factors, and Google has stressed multiple times that crawl budget, rate and limit are not any of these.
What it does do is get your site in order. On the other hand, it can get pretty technical, and you run the risk of potentially damaging your site if done incorrectly.
If you are going to go at it yourself, know your limits.
Apart from that, hopefully you’ll be able to get your site indexed as effectively as possible.
Author Biography
Tieece
As an SEO Executive at Kumo since 2015, Tieece oversees the planning and implementation of digital marketing campaigns for a number of clients in varying industries.
When he's not crawling sites or checking Analytics data, you'll often find him (badly) singing along to music that nobody else in the office is in to.
Tieece holds a number of digital marketing accreditations including Google Partners qualifications.
Company Number: 07865143 | Company VAT: 177073296