How to Implement Canonical Tags & Why
Posted: February 23rd, 2018

If content is king, then duplicate content is a really bad king, like King John. But, instead of losing lots of land in France, being excommunicated by the Pope and getting into a civil war, duplicate content signals to search engines that your site is of low quality and not worth ranking high.
For e-commerce sites, especially with the high number of pages there’ll be, and the similarity of several of the products can lead to a lot of duplicate content. This needs to be dealt with if you want search engines to look favourably upon your site. You could spend ages writing unique content for every single variant of product you’re selling, or you could save yourself loads of time and implement canonical tags.
What Is It & What Does It Do?
An HTML element that was first introduced in 2009 by various search engines. Also known as the rel=canonical element and the canonical link, it’s a way of telling search engines to ignore certain other pages in favour of one canonical page.
If you stick this HTML element on each of the duplicate pages, pointing towards your canon page, you are making it clear that your canon page is the one you want search engines to take notice of, not the other similar pages, ensuring that the duplicate content won’t be counted against your site. Depending on the amount of duplicate content you’ve got on your site, this could make a huge difference to your SEO.
Additionally, keyword cannibalisation is a potential outcome of not canonicalising. This is when you have multiple pages targeting the same keyword, and it often comes about because of duplicate content. This means that instead of having pages targeting different keywords and competing with other sites, you are forcing your pages to compete against each other. The effect of this is that they will all rank worse in the SERPs.
How to Implement It
It’s really simple to use canonical tags yourself. First, you need to identify the page you want to be the one that search engines look at. It could be the version that gets the most traffic, or you could just randomly choose one. All of the other similar pages will point to this page as the original version, ensuring the search engines overlook their duplicate content.
You’ll need to stick this HTML string in the header of each of the variant pages (the header is the bit of the HTML between <head> and </head>):
<link rel="canonical" href="https://my-site.co.uk/SEO">The bit in bold is whatever your canon page’s URL is. Having this tag in the headers of each of the variants ensures that search engines know that their content comes from the canon page, and it won’t be counted as duplicate.
An Example: Eight Colours of Trainer
It’s always handy to have examples when explaining how to do things. As an example of a canonical tag in action, let’s turn to Nike. They sell a lot of different trainers. Each type of trainer they sell will come in different colours, so there are going to be lots of pages which all have basically the same content. Inspecting the header of this page, you can see the canonical tag, helpfully circled in red:
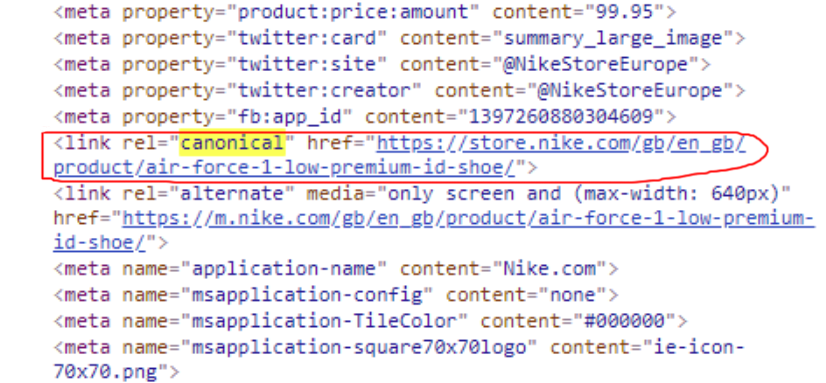
The canonical tag points to the URL page that Nike says is the canonical version. The difference between the URL of the page and the URL in the canonical tag is the query string (the bit after and including the question mark):
https://store.nike.com/gb/en_gb/product/air-force-1-low-premium-id-shoe/?piid=44456&pbid=535095068The canon page of these eight colour variants turns out to be the white and teal ones that say “PROSPERITY” on the soles, for whatever reason. To conclude, even though all of the content on the pages is the same across all eight variants, search engines will see the canonical tags on all the other pages pointing to the white and teal ones, so the content only appears once in the eyes of the search engine.
Self-Referential Canonicals
This is when you set the canonical page to also refer to itself as the canonical page, so you’d put the canonical tag on the canonical page, too. Why would you do this? Well, Google’s Webmaster Trends Analyst John Mueller has recommended (video below) that you should have a canonical link element on all of your pages to make sure you are protected from every single possible URL variant that will still take someone to your page. The main threat comes from the query string.
Basically, search engines allow you to type in any random query string after the URL, and you’ll still be brought to the site. For example, if I wanted to link to a particular trainer variant from my blog and accidentally typed the query string in wrong, then a search engine could crawl this link and be taken to this newly ‘birthed’ page that didn’t exist until I typed the query string wrong.
This new page can then be crawled by the search engine, and all of its content can be flagged as duplicate. To avoid this, just put a canonical tag on your canonical pages, so that they reference themselves.
A Couple of Dos and Don’ts
- DO self-canonicalise your homepage, just to make sure that there is no way that the search engine can be confused when it comes to this
- DON’T make one page the canon page, but then make that page refer to another page as the canon page. You’re sending mixed signals, and search engines might interpret that in any number of ways
- DON’T do a 301 redirect instead. A 301 redirect would force your audience to go to the page that the 301 goes to, so they’d never get to the particular variant of the product they wanted to see. They’re not the same thing
Conclusion
Canonical tags are quick and easy to implement (depending on the number of pages you have, but some CMS have plug-ins to let you do it for multiple pages at a time) and they can make a huge difference to how search engines see your site. You’ll go from a site that they think is untrustworthy and full of duplicate content to one with far less duplicate content.
Author Biography
Nick
Company Number: 07865143 | Company VAT: 177073296