What is Duplicate Content?
Posted: December 21st, 2018
As we continue to explore the fundamentals of SEO, we are going to take a look at duplicate content and what it means for your website. To ensure that you can completely avoid the negative effects that duplicate content can have, let’s start by going right back to basics.
What is duplicate content?
To put it simply, duplicate content is content which appears in more than one place on the internet. Now, this may sound harmless enough, but it can actually have a detrimental effect on how your site ranks in search engine results.
When does duplicate content occur?
It may sound obvious to you that copying other people’s words or work for your website isn’t a great idea. But, you may be surprised to hear that a 2015 study found that, on average, websites contain 29% duplicate content.
This is because duplicate content can occur for a range of reasons; it can come from blatant copying from other sites, as well as poorly edited copied content. But, it can also happen if your website contains more than one page covering the same subject, when a page on your site can be accessed by different URLs, or if you are using a multiple-site strategy.
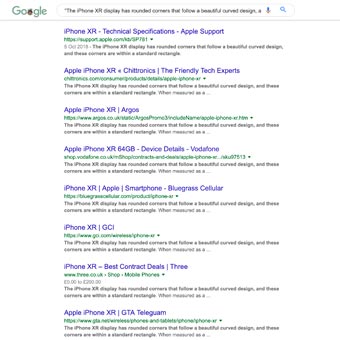
Duplicate content: Why does it matter?
Ultimately, duplicate content matters as it makes it more difficult for consumers to find your site. Whilst it doesn’t actually incur a penalty from Google, the search engine can be confused, as it is difficult to determine which source is most relevant for a query. This burns crawl budget and can result in your website ranking lower in search results.
What’s the confusion?
As there is no actual penalty implemented by Google, there can be quite a lot of confusion around duplicate content. However, Google have stated that uniqueness in content is rewarded, meaning that anything non-unique will, by default, not be ranked highly.
Google have also said that “the lowest rating is appropriate if all, or almost all, of the main content is copied”. Whilst Senior Webmaster Trends Analyst at Google, John Mueller, has added that “we do have some things around duplicate content… that are penalty worthy”. Going on to say that, duplicate content, which is obviously spammy, will even result in a website being completely removed from search.
What are the effects of duplicate content on search engines?
- Search engines don’t know which version of the content to include (or exclude) in search results
- They don’t know which page should rank more highly
- They don’t know whether to direct link metrics (e.g authority) to one page, or separate between both
What are the effects of duplicate content on sites?
- Lower search results ranking
- Less visibility to consumers
- Decreased traffic to the site
How to avoid duplicate content creation
Now that you understand the issues surrounding duplicate content, here’s how you can avoid it.
- Spend time creating inspiring, unique content – it may sound obvious, but it can be the reason behind many websites’ downfall when it comes to duplicate content. Well-thought-out, researched articles are unlikely to contain duplicate content and will rank more highly
- Check for plagiarism – there is a whole host of sites and services available which are designed specifically to check your work for duplicate content. Simply checking your work on a site such as Copyscape before sharing it will ensure that your work, or something very similar, is not already online
- Canonicalise URLs which point to the same page – adding the rel=canonical attribute to the HTML head of the page will let Google know which page you want to rank for this content.
- Set up a 301 redirect – do this from the duplicate page to the one you want to rank
- Add a self-referential rel=canonical link to your existing pages – this will prevent content scrapers from stealing your content and ranking above you for it
We hope you’ve found this a useful introduction to the risks associated with duplicate content online. For more information about SEO, have a look at the rest of our Beginner’s SEO series!
Author Biography
Emma
Emma started working at Kumo in the summer of 2018 after graduating from Nottingham Trent University. She is a keen reader and uses her love of books to help her create engaging content for all of Kumo’s clients.
When she’s not writing, she enjoys running, yoga and keeping up-to-date with the latest fashion news.
Company Number: 07865143 | Company VAT: 177073296