A Beginner’s Guide to the Screaming Frog Tool
Posted: March 14th, 2018
Screaming Frog is a great tool for crawling a site and identifying any issues or potential issues that are present. It’s one of the most popular crawlers available and for good reason.
With an ability to highlight and report on a whole host of factors, Screaming Frog can help take your onsite SEO to the next level. If you’re new to SEO or to Screaming Frog, this article might help steer you in the right direction.
Inititate the Crawl
Load Screaming Frog and enter your site’s web address; subdomains and subfolders work, too. It’ll then take a few moments to crawl the site. It might take longer than a few minutes, depending on the size of your site.
Along the top, you’ll see a number of tabs, showing the different areas of crawled information. As you can see, there are quite a lot of them. That gives you an idea of just how much Screaming Frog covers.

Internal Tab – Site Resources
The internal tab lists all the resources Screaming Frog comes across that belong to your site, subdomain or subfolder. By default, it’s the first tab you’ll see when running your crawl.

You can filter these resources by HTML, JavaScript, CSS, Images, PDF, Flash and Other.
External Tab – Outbound Links
Go to the External tab to see all of the outbound URLs that you have on your site. These could be outbound href links or external images, embeds, JavaScript or CSS resources. The same filter options are available as in the Internal tab.
It’s usually a case of seeing the sites and resources you’ve linked out to here. However, if there are any that you do not recognise or just look a bit suspicious, then take a look at them to see what they are.
In very rare cases, sites have been hacked in order to inject links to other sites.
Or, perhaps you have a comment system which allows for links in usernames or comments. Checking your outbound links means that you can either remove them or NoFollow them.
Protocol Tab – Consistent HTTP and HTTPS
Go to the Protocol tab on Screaming Frog and filter by HTTP or HTTPS to see if your site is running resources over an inconsistent protocol.
If your site is using both HTTP and HTTPS versions of pages without proper care, user experience, as well as content can be affected. Search engines tend to treat http and https versions of the same site and its pages as completely different properties.
Assuming you have an SSL certificate, HTTP resources can render your pages ‘unsecure’, leading to ‘Not Secure’ warnings appearing in Chrome and other browsers.
External resources are also listed under this tab, so don’t panic if they are inconsistent. Just ensure that your internal links, pages and resources are all using a uniform protocol.
Response Codes – Redirects, Dead Links and Server Errors
The Response Codes tab, as you might imagine, details the response codes that the spider encountered whilst crawling the site.
The three you’ll mainly want to focus on are Redirection (3xx), Client Error (4xx) and Server Error (5xx).
Redirection (3xx)
A 3xx response code indicates that when a URL is clicked, a browser will eventually end up at a different destination. There are a number of ways redirections can be implemented. At a basic level, 301 redirects (permanent) and 302 redirects (temporary).
In 2016, Google revealed that 301 redirects no longer result in a lower PageRank (the now secret indicator of web page authority), which is good if your site has a lot of 301s.
However, it’s still not good practice to have 301s, and PageRank is not the only indicator of SEO performance and using them brings risks. For example, Google will treat pages that are 301 redirected to irrelevant pages the same as 404s.
With that in mind, it’s a good idea to remove any unnecessary 301s and ensure that your internal links point to the right pages.
302 Redirects indicate a temporary change. They pass no link value and tell search engines that the original page is still the big dog. You’ll want to avoid these as much as possible.
Client Error (4xx)
Search engines will reward you if your site has a good user experience. 404 pages are basically a dead end for users and crawlers alike. ‘The page you are looking for cannot be found’ – it’s not exactly a helpful message. It is always better to redirect to another page when possible.
That’s why it’s important that you see if any of your internal links are resulting in 404 errors, and you update them, replacing dead links with live links. Be sure that the new target page is relevant, though. Otherwise, it might be a better idea to remove the link altogether.
Server Error (5xx)
These should be rare and extremely minimal if present. Usually a result of a non-responsive server, caching issues or crawling permissions, carefully check for server errors and potential reasons.
Page Titles – Missing, Duplicate and Truncated Titles
What you write in your <title></title> tag in the header of your site is one of the most important SEO factors when it comes to users. Search engines do take them into account, but it’s far more for the benefit of users.
Your page title is what comes up in the search results, so you’d better include your keywords and make it as enticing as possible for users. Using Screaming Frog, go to the Page Titles tab to see the entire list of your page titles for your various pages.
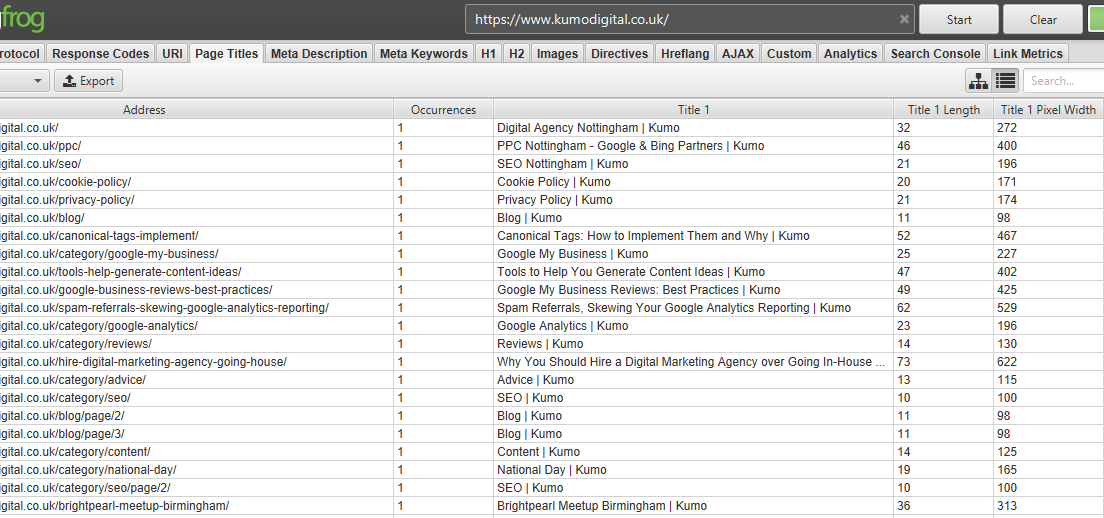
As a rough guide, Google will display around 60-70 characters, or 571 pixels, of a page title before truncating it. Users generally want to see the whole title of the page they might click on, so you should ensure that your title is within these limits.
Screaming Frog also lets you filter by ‘Missing’, so you can make sure that none of your pages have no title. You can filter by ‘Duplicate’, too. You don’t want any duplicate titles because that means that you’ve likely got multiple pages competing for the same keyword, which is bad news.
Meta Descriptions
Along with page titles, meta descriptions are a crucial way to encourage users to click on your page on the SERPs. Meta descriptions don’t technically act as a ranking factor, but they can have a huge impact on the click-through rate.
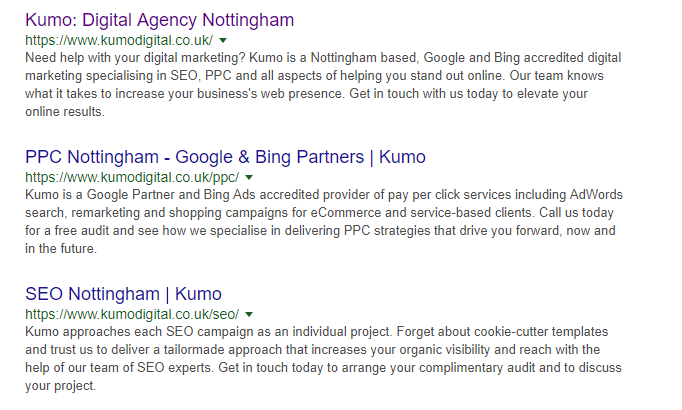
You can use Screaming Frog to list your missing, duplicate and long meta descriptions – just go to the ‘Meta Description’ tab. You have about 320 characters to play with to create a keyword-rich and compelling meta description that’s going to encourage clicks.
Portent’s SERP Preview tool (https://www.portent.com/serp-preview-tool) does a great job of previewing titles and meta descriptions when it comes to writing new metadata.
H1 & H2 – Heading Tags
These are both fairly important to SEO, and it’s important to use them correctly. Every page on your site needs to have an H1 tag. It tells users what the rest of the page’s content is going to be about and encourages them to keep reading.
Your H2S, on the other hand, are your subheadings that separate your content into various sections.
You can use Screaming Frog to see if you have any H1S missing from any of your pages. Just click on the H1 and H2 tabs.
Best practice is to make sure that your H1 and H2 tags are accurate and descriptive. Don’t go mad with H2S, just use as many as you need; one for each section.
You’ll also want to try and avoid duplicating H1 and H2 tags across multiple pages.
Images
SEO also encompasses site performance, and one way to slow down your site is to have your pages be full of large, unoptimised images.
Go to the Images tab on Screaming Frog. You’ll find that you can filter by images over 100kb, missing alt text and alt text over 100 characters.
Images over 100 kb may need optimising to improve performance, but don’t fall into the trap that all of them do. Some optimised images are over 100 KB because of their dimensions and quality.
A quick trick is to enter a URL on which the image appears (you can find this by highlighting an image and clicking Inlinks from the bottom menu) through a page speed tool, such as PageSpeed Insights (https://developers.google.com/speed/pagespeed/insights/) or GTmetrix (https://gtmetrix.com/). They’ll let you know if you can optimise your images.


As advanced as they might be, search engines do not yet fully understand what images are just by looking at them, so help them out by describing them with alt tags.
Directives – Canonical and Robots Tags
We’ve already gone into why canonical tags are important and how to implement them. In the Directives tab on Screaming Frog to filter by ‘Canonical’, ‘No Canonical’, Canonicalised and ‘Self Referencing Canonical so you can see the exact state of your pages’ canonical tags.
Amongst other elements, you’ll also be able to view pages with Index, NoIndex, Follow and NoFollow tags. Checking these over can ensure that pages marked with NoIndex tags have been done so intentionally.
Stay on the ‘Directives’ tab and filter by ‘NoIndex’ or ‘NoFollow’. These are important tags for hiding certain pages from users and for conserving and making the best use of your allocated crawl budget.
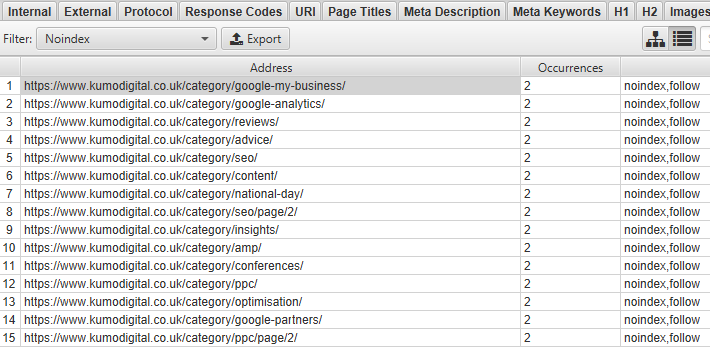
Moving on to NoFollow, a search engine will follow all of the links on a page when it crawls it, using up some of its crawl budget for the site. If you want to conserve your crawl budget for other pages on your site, then you can use NoFollow tags on links to stop the search engine from following particular links or links on an entire page.
A Basic Understanding… For Now
As far as a basic guide goes, this pretty much covers most of what Screaming Frog offers. In the future, we’ll be putting together a more advanced guide (and it gets pretty advanced), which allows you to get hands-on with some of the more technical aspects of SEO.
In the meantime, get accustomed to this great spider and use it to improve your site and SEO.
Author Biography
Nick
Company Number: 07865143 | Company VAT: 177073296